CDF 累积分布函数
给定同一个维度的一堆数值,比如说 API 请求的耗时,想要知道系统的性能指标;再比如说一个购物商城上每个用户的购物车中物品的数量,想要知道用户购物时一般会添加多少个物品等等。
以后一个为例,第一反应可能是用户最大可能放多少个(边界),然后算一下平均值。但是我们知道平均值可能会被某个个例的值拉大或者缩小,所以经常听到去掉最大值和最小值之后再算平均数。也有人计算中位数,毕竟中位数可以表示 50% 的数值比它小或者比它大。不管是平均数还是中位数,他们的问题是没有办法看出数据的离散程度,很容易受小群体的数值影响结果,所以计算平均数时还要计算方差,通过计算每个值与期望(平均值)来反映数据的离散程度。一个更好的办法是使用 CDF,最近在做数据统计时突然才想起来的,以前在风行的时候经常画 CDF 图。
CDF,即累积分布函数,反映随机变量的概率分布,专业的定义在 这里,就不赘述了。还是通过例子来说明吧。
随机生成 200 个数字用来表示 200 个购物车里物品的数量,代码如下:
#!/usr/bin/env python3 import matplotlib.pyplot as plt # 样本 data = [ 1, 2, 3, 1, 5, 6, 7, 8, 9, 10, # 10 2, 2, 5, 4, 1, 1, 7, 8, 9, 1, # 20 2, 2, 1, 2, 1, 1, 7, 1, 8, 15, # 30 4, 2, 1, 2, 1, 2, 4, 1, 8, 2, # 40 8, 1, 2, 2, 1, 2, 4, 1, 9, 3, # 50 7, 1, 1, 1, 1, 2, 4, 1, 7, 5, # 60 10, 2, 3, 1, 5, 2, 1, 1, 9, 8, # 70 9, 1, 3, 1, 5, 6, 7, 1, 4, 7, # 80 1, 2, 2, 2, 3, 6, 1, 1, 4, 1, # 90 1, 1, 1, 2, 3, 6, 7, 1, 9, 3, # 100 5, 1, 2, 2, 1, 4, 2, 8, 3, 2, # 110 4, 1, 1, 2, 2, 4, 7, 8, 2, 8, # 120 3, 2, 1, 2, 3, 4, 7, 3, 1, 20, # 130 2, 2, 1, 3, 1, 6, 2, 3, 1, 4, # 140 1, 2, 1, 3, 2, 6, 2, 3, 1, 3, # 150 2, 1, 1, 4, 3, 6, 2, 3, 1, 2, # 160 3, 1, 1, 3, 1, 1, 1, 8, 2, 1, # 170 4, 1, 1, 1, 1, 1, 1, 1, 2, 1, # 180 4, 2, 3, 1, 10, 1, 1, 1, 2, 3, # 190 4, 2, 3, 1, 10, 1, 1, 1, 2, 5, # 200 ] # 从小到大排序 data.sort() print(data) # 计算占比 sample = [x for x in range(data[0], data[-1]+1)] it = 0 x, y = [], [] for idx in range(len(sample)): while it < len(data): if data[it] > sample[idx]: break it += 1 x.append(sample[idx]) y.append(it/len(data)*100) print(x, y) # 画图 fig, ax = plt.subplots() ax.plot(x, y) ax.fill_between(x, y) ax.set(xlabel='count', ylabel='percent(%)', title='pre shopping CDF') plt.xlim(x[0], x[-1]) plt.xticks(x) plt.ylim(0, 100) plt.grid() plt.show()
生成如下图片:
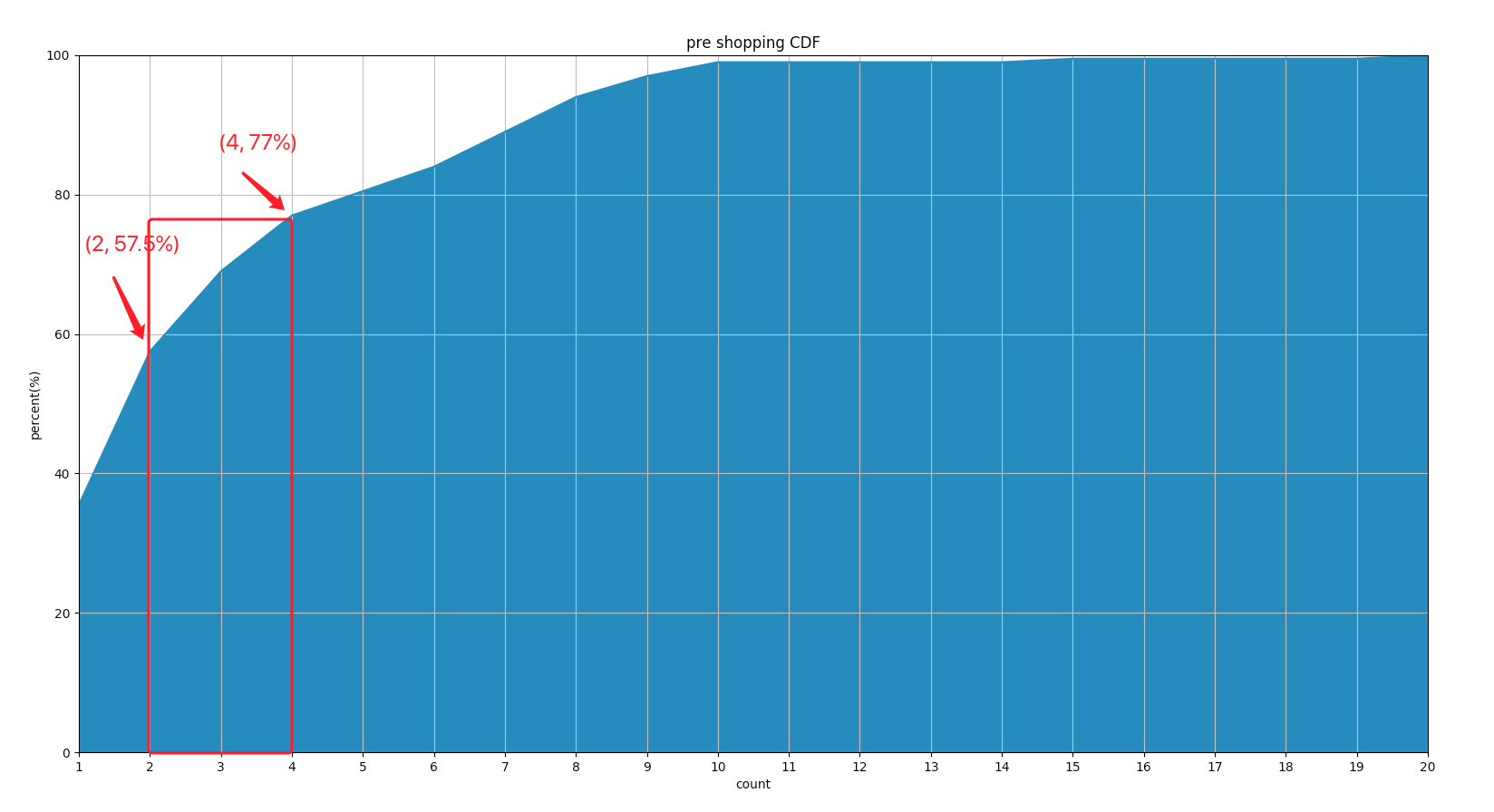
CDF 表示的概率分布,比如上面的两个标注:
- 第一个表示购物车中商品数量小于等于 2 个的购物车概率为 57.5%
- 第二个表示购物车中商品数量小于等于 4 个的购物车概率为 77%
依次类推,面积表示的离散数据在该区域的概率,最终所有的数据的概率为 100%,这样就可以知道购物车中任意商品数量个数的占比。如果想知道某个区间的概率怎么办呢?做差即可,从上图可以看出,大于购物车中物品数量大于 2 小于等于 4 的概率是 =77%-57.5%=,即 12.5%(红色区域)。
计算累积分布还是麻烦一些,在有些业务场景下,只需要关心核心的几个值行了,比如在做性能测试时关心 99% 的请求速度是否能小于 100ms 等,相当于是 cdf 图中的某一个点,也有称这种统计方法叫 TP值(Top Percentile)。